Berkeley Scientists Create First 3-D Map of Protein Universe
The universe has been mapped! Not the universe of stars, planets, and black holes, but the protein universe, the vast assemblage of biological molecules that are the building blocks of living cells and control the chemical processes which make those cells work. Researchers with the Lawrence Berkeley National Laboratory (Berkeley Lab) and the University of California at Berkeley have created the first three-dimensional global map of the protein structure universe. This map provides important insight into the evolution and demographics of protein structures and may help scientists identify the functions of newly discovered proteins.
Sung-Hou Kim, a chemist who holds a joint appointment with Berkeley Lab’s Physical Biosciences Division and UC Berkeley’s Chemistry Department, led the development of this map. An internationally recognized authority on protein structures, he expressed surprise at how closely the map, which is based solely on empirical data and a mathematical formula, mirrored the widely used Structural Classification System of Proteins (SCOP), which is based on the visual observations of scientists who have been solving protein structures.
“Our map shows that protein folds are broadly grouped into four different classes that correspond to the four classes of protein structures defined by SCOP,” Kim says. “Some have argued that there are really only three classes of protein fold structures but now we can mathematically prove there are four.”
Protein folds are recurring structural motifs or “domains” that underlie all protein architecture. Since architecture and function go hand-in-hand for proteins, solving what a protein’s structure looks like is a big step towards knowing what that protein does.
The 3-D map created by Kim and his colleagues is described in the February 17, 2003 edition of the Proceedings of the National Academy of Sciences. It shows the distribution in space of the 500 most common protein folds as represented by points which are spatially separated in proportion to their structural dissimilarities. The distribution of these points reveals a high-level of organization in the fold structures of the protein universe and shows how these structures have evolved over time, growing increasingly larger and more complex.
“When the structure of a new protein is first solved, we can place it in the appropriate location on the map and immediately know who its neighbors are and its evolutionary history which can help us predict what its function may be,” Kim says. “This map provides us with a conceptual framework to organize all protein structures and functions and have that information readily available in one place.”
With the completion of a “working draft” of the human genome in which scientists determined the sequences of the three billion DNA bases that make up the human genome, the big push now is to identify coding genes and the molecular and cellular functions of the proteins associated with them. Coding genes are DNA sequences that translate into sequences of amino acids which RNA assembles into proteins.
The prevailing method for predicting the function of a newly discovered protein is to compare the sequence of its amino acids to the amino acid sequences of proteins whose functions have already been identified. A major problem with relying exclusively on this approach is that while proteins in different organisms may have similar structure and function, the sequences of their amino acids may be dramatically different.
“This is because protein structure and function are much more conserved through evolution than genetically based amino acid sequences,” Kim says.
Kim has been a leading advocate for grouping proteins into classes on the basis of their fold structures and using these structural similarities to help predict individual protein functions. While the protein universe may encompass as many as a trillion different kinds of proteins on earth, most structural biologists agree there are probably only about ten thousand distinctly different types of folds.
“A smaller number of new protein folds are discovered each year despite the fact that the number of protein structures determined annually is increasing exponentially,” Kim says. “This and other observations strongly suggests that the total number of protein folds is dramatically smaller than the number of genes.”
The rationale behind this idea is that through the eons, proteins have selectively evolved into the architectural structures best-suited to do their specific jobs. These structures essentially stay the same for proteins from all three kingdoms of life — bacteria, archaea, and eukarya — even though the DNA sequences encoding for a specific type of protein can wildly vary from the genome of one organism to another, and sometimes even within the same organism.
In the map created by Kim and his colleagues, elongated groups of fold distributions approximately corresponding to the four SCOP structural classifications can be clearly seen. These classifications, which are based on secondary structural compositions and topology are the “alpha” helices, “beta” strands, and two mixes of helices and strands, one called “alpha plus beta” and the other “alpha slash beta.” The Berkeley map reveals that the first three groups share a common area of origin, possibly corresponding to small primordial proteins, while the “alpha slash beta” class of proteins does not emerge until much later in time.
“It is conceivable that, of the primordial peptides, those containing fragments with high helix and/or strand propensity found their way to fold into small alpha, beta, and alpha plus beta structures,” Kim says. “The alpha slash beta fold structures do not appear until proteins of sufficient size rose through evolution and the formation of supersecondary structural units became possible.”
Since understanding the molecular functions of proteins is key to understanding cellular functions, the map developed by Kim and his colleagues holds promise for a number of areas of biology and biomedical research, including the design of more effective pharmaceutical drugs that have fewer side-effects.
“This map can be used to help design a drug to act on a specific protein and to identify which other proteins with similar structures might also be affected by the drug,” Kim says.
For the next phase of this research, Kim and his colleagues plan to tap into the supercomputers at Berkeley Lab’s National Energy Research Scientific Computing Center (NERSC) to add the rest of the some 20,000 and counting known protein structures to their map. They also plan to set up a Website where researchers can submit for inclusion new protein structures they have solved.
Working with Kim on this protein universe mapping project have been Jington Hou, Gregory Sims, and Chao Zhang. The protein was funded by grants through the National Science Foundation and the National Institutes of Health.
Berkeley Lab is a U.S. Department of Energy national laboratory located in Berkeley, California. It conducts unclassified scientific research and is managed by the University of California. Visit our Website at www.lbl.gov/.
Additional Information
Sung-Hou Kim can be reached at (510)486-4333 or by e-mail at SHKim@lbl.gov
His Website can be visited at
http://www-kimgrp.lbl.gov/
Media Contact
All latest news from the category: Life Sciences and Chemistry
Articles and reports from the Life Sciences and chemistry area deal with applied and basic research into modern biology, chemistry and human medicine.
Valuable information can be found on a range of life sciences fields including bacteriology, biochemistry, bionics, bioinformatics, biophysics, biotechnology, genetics, geobotany, human biology, marine biology, microbiology, molecular biology, cellular biology, zoology, bioinorganic chemistry, microchemistry and environmental chemistry.



Newest articles
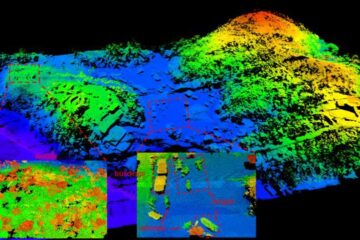
Airborne single-photon lidar system achieves high-resolution 3D imaging
Compact, low-power system opens doors for photon-efficient drone and satellite-based environmental monitoring and mapping. Researchers have developed a compact and lightweight single-photon airborne lidar system that can acquire high-resolution 3D…

Simplified diagnosis of rare eye diseases
Uveitis experts provide an overview of an underestimated imaging technique. Uveitis is a rare inflammatory eye disease. Posterior and panuveitis in particular are associated with a poor prognosis and a…

Targeted use of enfortumab vedotin for the treatment of advanced urothelial carcinoma
New study identifies NECTIN4 amplification as a promising biomarker – Under the leadership of PD Dr. Niklas Klümper, Assistant Physician at the Department of Urology at the University Hospital Bonn…

