Sound research at acoustical society meeting
The latest news and discoveries from the science of sound will be featured at the 162nd meeting of the Acoustical Society of America (ASA) held October 31 – November 4, 2011, at the Town and Country Hotel in San Diego, Calif. Experts in acoustics will present research spanning a diverse array of disciplines, including medicine, music, speech communication, noise, and marine ecology.
Journalists are invited to attend the meeting free of charge. Registration information is at the end of this release. Lay-language versions of more than 50 presentations will be available at the ASA's Worldwide Press Room (www.acoustics.org) approximately one week before the meeting.
Webcast: News Briefing – Meeting Highlights: Journalists working remotely are invited to participate in a webcast on Monday, October 31, at 11 a.m. EDT (8 a.m. PDT). Scientists will present brief summaries of their research and answer questions. An agenda and list of presenters will be released shortly. Reporters on site are invited to participate in person. Register for the webcast here: http://www.aipwebcasting.com.
The following summaries highlight a few of the meeting's many noteworthy talks.
Highlights: Monday, October 31
Acoustical archeology reveals sounds of Renaissance Venice: The Renaissance period of Venice, Italy, is famed for its vast architectural and musical masterpieces. It was during this time that music became more complex and choirs were separated to produce the first “stereo” effect in Western history. To better understand both the music and the role of architecture in the acoustics of this period, a research team used a combination of historical evidence and scientific modeling to listen to music as it would have sounded in the churches of Venice 400 years ago. The research was conducted by Braxton Boren, a Ph.D. student in music technology at New York University, and Malcolm Longair, a physics professor at the University of Cambridge. “We built a filter for the churches' acoustics as they would have existed in the 16th century,” explains Boren. “Then we can record a choir singing in an anechoic chamber, with no sound reflections, and put it through the filter to hear the choir as it would have sounded during the Renaissance.” The presentation 1aAA6, “Acoustic simulation of Renaissance Venetian churches,” is in the morning session of Monday, Oct. 31.
Abstract: http://asa.aip.org/web2/asa/abstracts/search.oct11/asa6.html
Unexploded ordnance detected via low-frequency acoustics: Many bodies of water around the globe contain discarded and unexploded munitions, a.k.a. “underwater ordnance” or “UXOs.” These UXOs, most commonly associated with former military training sites or the result of post-war disposal, pose public safety hazards as well as chemical contamination risks. Cleanup requires being able to locate and differentiate engineered objects from natural ones. Aubrey España, a research associate in the Acoustics Department of the University of Washington's Applied Physics Laboratory, and colleagues are working on a way to do just that, thanks to low-frequency acoustics. Sound is a particularly useful tool for classifying objects either on or embedded in the ocean floor. “Low-frequency sound has the advantage of being able to excite specific vibrations of an object of interest, which in turn results in re-radiation of sound back to the observer,” explains España. “This scattered sound is used to generate an acoustic template or fingerprint of the object, which can aid in distinguishing between man-made and natural objects.” According to España, the research not only aims to generate acoustic fingerprints for various objects, but also to understand the physics behind what we see in the acoustic fingerprint – such as how sound couples to the object/UXO, the subsequent vibration that ensues, and how the sound radiates from the object back to the viewer. The presentation 1aUW2, “Acoustic scattering from unexploded ordnance in contact with a sand sediment: Mode identification using finite element models,” is in the morning session on Monday, Oct. 31.
Abstract: http://asa.aip.org/web2/asa/abstracts/search.oct11/asa57.html
Student test scores suffer from even subtle background noise: Teachers do all they can to provide a productive learning experience for their students, but some factors are beyond their control and may actually be dragging down standardized test scores. According to research on third- and fifth-grade classrooms, fifth-grade students were found to have lower reading test scores in classrooms with higher background noise. A similar negative trend was observed between the fifth-grade language achievement test scores and background noise levels. The noise the researchers measured and compared to test scores was not the expected cacophony of nearby traffic or occasional outbursts from unruly students. Instead the noise came from the steady droning and humming of the air conditioning and heating systems. “Our research shows that many students are forced to learn and teachers are required to work in conditions that simply do not aid in the learning experience,” said Lauren M. Ronsse, now with the U.S. Army Engineer Research and Development Center in Champaign, Ill. She and her doctoral advisor Lily M. Wang of the University of Nebraska at Lincoln measured the background noise in 67 unoccupied third- and fifth-grade classrooms in a Nebraska public school district. After the measurements were completed, the researchers compared the background noise levels of the classrooms to the standardized student achievement scores. They observed statistically significant correlations among the fifth-grade students, though the negative effect was not observed among the third-grade students. The presentation 1aAA9, “Impacts of classroom acoustics on elementary student achievement,” will be presented in the morning session on Monday, Oct. 31.
Abstract: http://asa.aip.org/web2/asa/abstracts/search.oct11/asa9.html
Highlights: Tuesday, November 1
Chimpanzee studies suggest speech perception ability not a uniquely human trait: Experience is a powerful teaching tool: practice remodels neural connections and leads to mastery. Now scientists suggest that it is early experience with language – and not special innate cognitive ability – that allows humans to process and perceive speech while their closest evolutionary relatives, chimpanzees, do not. Traditionally, the human brain has been thought to be uniquely adapted to perceive and process speech patterns, a trait widely regarded as an evolutionary phenomenon separating humans from other primates. However, a 25-year-old language-trained chimp named Panzee has recently demonstrated the ability to interpret highly distorted speech sounds in a similar manner to humans. These data provide evidence that the capacity for speech perception may have existed in a common ancestor. “I think our results just reinforce the fact that experience matters. Humans maybe do not perceive speech because they are human, but instead because of the tremendous amount of experience they have with it from birth,” explains Lisa Heimbauer, a Ph.D. candidate and researcher at Georgia State University's Language Research Center. Heimbauer and her colleagues, Drs. Michael Owren and Michael Beran, also of Georgia State University, hope to better understand the mechanisms used by young children to process and produce speech. The presentation 2aAB9, “A chimpanzee responds best to sine-wave speech with formant tones 1 and 2 present,” will be in the morning session on Tuesday, Nov. 1.
Abstract: http://asa.aip.org/web2/asa/abstracts/search.oct11/asa179.html
Teaching automatic speech recognition engines what humans already know: Sorting sound into intelligible speech is a seemingly effortless feat. Healthy human ear-brain auditory systems perform it heroically, even in highly confusing soundscapes with a riotous mix of acoustic signals. And while scientists have successfully constructed automatic speech recognition engines to help perform routine speech transactions, they have problems and, too often, garble prevails. A team from the International Computer Science Institute at the University of California, Berkeley, and from the University of Oldenburg, Germany, is learning from errors in human speech recognition and applying that knowledge to design new signal processing strategies and models for automatic speech recognition. One key finding: automated recognition does not handle time cues in language as well as human recognition does. Improving computer models to optimize the way automated processes time variation in speech to align it with the human system could have beneficial applications in many human-machine interfaces. These range from improved hearing aids and smart homes to new assistive hearing apps on smart phones. Explains lead researcher, Bernd T. Meyer, Ph.D.: “Automatic speech recognition has its flaws. In comparison, human speech recognition works a lot better, so we thought, 'Why don't we try to learn from the auditory system and integrate those principles into automatic recognition?'” The presentation 2pSCa2, “Improving automatic speech recognition by learning from human errors,” will be in the afternoon session on Tuesday, Nov. 1.
Abstract: http://asa.aip.org/web2/asa/abstracts/search.oct11/asa379.html
Highlights: Wednesday, November 2
Seeing speech: High-speed video imaging for improved voice health: When we talk, the delicate tissues of the voice box vibrate faster than the eye can see. Now researchers and physicians are finally able to visualize and investigate this physiological feat, thanks to the development of a high-speed imaging system by a research team at the Center for Laryngeal Surgery and Voice Rehabilitation at the Massachusetts General Hospital. The team's goal is to improve vocal health by understanding the movements of the vocal folds. Using the same high-speed video technology that enables nature photographers to visualize the rapid beating of hummingbird wings, the Boston team has begun to observe and document details of vocal vibrations and voice acoustics that have never before been appreciated during clinical evaluations. Explains research team member Dr. Daryush Mehta, “For the first time, voice scientists are able to investigate detailed relationships between vocal vibrations and sound qualities of the human voice. For example, we are just now discovering that certain asymmetric vibration patterns do not necessarily degrade one's voice acoustics as once thought.” This level of detail is possible due to recent technological advances in high-speed imaging of the larynx. It enables researchers to capture and analyze more than 10,000 images per second – of vocal fold oscillations that occur 100 to 1,000 times per second. This team's work grew out of an urgent need to assess the true vibratory characteristics of vocal fold bio-implants that are currently under development at the Massachusetts General Hospital Voice Center. The presentation 3aSCa1, “Use of laryngeal high-speed videoendoscopy systems to study voice production mechanisms in human subjects,” is in the morning session on Wednesday, Nov. 2.
Abstract: http://asa.aip.org/web2/asa/abstracts/search.oct11/asa513.html
Human voice conveys stress level: Men and women respond differently to stress: By evaluating the acoustical properties of the human voice, a research team at the University of Florida, Gainesville, is expanding the scientific understanding of the physics of vocal stress – insight that might one day be used to improve the detection of deception. The research team confirmed that the human voice changes in systematic and perceptible ways under carefully measured, significant stress levels. One early surprise finding is that men and women respond differently to the same stressors. “In male subjects, higher degrees of physiological arousal were underreported – what you might call a 'tough guy' response,” explains lead researcher, James Harnsberger, Ph.D., a speech scientist in the Department of Linguistics. A graduate student on the project, Christian Betzen, suggested analyzing separately the gender categories for the four stress metrics used in the study – two physical and two self-reporting. “The results were a surprise. We had expected that higher stressors would prompt both increased physiological response and increased self-reported stress levels in all test subjects fairly uniformly for both men and women,” Dr. Harnsberger explains. One early conclusion these data suggest is that acoustic analyses should include gender in the study design. Talk 3aSCb44, “Talker and gender effects in induced, simulated, and perceived stress in speech,” is in the morning session on Wednesday, Nov. 2.
Abstract: http://asa.aip.org/web2/asa/abstracts/search.oct11/asa568.html
Highlights: Thursday, November 3
Ear anatomy may amplify irritating tones of chalkboard squeak: The sound of fingernails on a chalkboard sets many people's teeth on edge, and now a team of researchers from the University of Cologne in Germany and the University of Vienna in Austria think they know why. In a study designed to pinpoint the source of this and similarly irritating sounds, scientists found that the most obnoxious elements of the noises may be amplified by the shape of the human ear. In the study, scientists removed information from audio clips of people scraping their nails or bits of chalk against a chalkboard and played these modified clips to willing participants. The human ear is known to be particularly sensitive to pitches in the mid- to low-level range of frequencies, between 2000 Hertz and 4000 Hertz, which is the peak of human hearing. It turns out that when scientists removed all the pitch information in this range from the audio recordings, the study participants rated the noises as more pleasant than other versions of the sounds. So chalkboard squeak may be irksome because the most obnoxious elements of the sound sit right in the sweet spot of human hearing. Talk 4pPP6, “Psychoacoustics of chalkboard squeaking,” is in the afternoon session on Thursday, Nov. 3.
Abstract: http://asa.aip.org/web2/asa/abstracts/search.oct11/asa888.html
Physicists shoot 'gunshot forensics' forward into science: The characteristic crack and bang of a gunshot blast may contain vital clues about a crime: who shot first, or even what type of firearm did the deed. But dozens of factors, from the angle and direction of the gun's muzzle to the quality of the microphone, can change the way a gunshot sounds in a recording, making it difficult even for expert analysts to tell exactly what went down at the scene of the crime. Now researchers from BAE Systems in Austin, Texas, and the FBI Forensic Audio and Video Analysis Unit have taken a major step toward improving scientists' understanding of how the sound of gunshots corresponds to the manner in which the bullets were fired. “The field of forensic gunshot analysis is relatively new,” said Steven Beck, principal scientist for BAE Systems. “[Analysts] get these recordings” – often from cell phones or other devices with limited recording capabilities – “and they have to try to figure out what's going on. If you don't understand [the impact of] all these variations, you can make the wrong conclusions,” Beck said. In a controlled laboratory environment, the researchers placed microphones at a range of angles and distances from each blast, to catch the sound pattern of a single round from multiple points of view. Talk 4aSCa3, “An introduction to forensic gunshot acoustics,” is in the morning session on Thursday, Nov. 3.
Abstract: http://asa.aip.org/web2/asa/abstracts/search.oct11/asa760.html
Highlights: Friday, November 4
Vuvuzelas: Earplugs recommended: Vuvuzelas blasted into the publics' ears and awareness during the 2010 FIFA World Cup in South Africa. One immediate question asked was: Do vuvuzelas, those cheap horns commonly made of plastic and blown by enthusiastic fans during sporting events, pose serious risks to hearing? What the Southern Polytechnic State University (SPSU) and Georgia Institute of Technology (Georgia Tech) researchers found is that the sound levels from single horns ranged from 90 to 105 decibels at the players' ears. They also discovered that the horns' impact is greatest when blown simultaneously with many others, such as at the World Cup, where the levels within an audience may well approach 120 decibels. “For perspective, 100 decibels is the level of noise you'd hear at a rock concert. An ambulance siren or pneumatic jack hammer produce about the same level of noise as the vuvuzelas in a stadium, 120 decibels, which is at the threshold of feeling and produces a tickling sensation in your ears,” explains Richard Ruhala, associate professor and program director of mechanical engineering at SPSU. “The threshold of pain is 140 decibels. Sustained exposure to 120 decibels is 1000 times the acoustic energy that causes hearing loss (with long-term exposure). That's why OSHA [Occupational Safety and Health Administration] requires people working near those noise levels to wear hearing protection.” Presentation 5aNSb1, “Vuvuzelas and their impact,” is in the morning session on Friday, Nov. 4.
Abstract: http://asa.aip.org/web2/asa/abstracts/search.oct11/asa977.html
High frequencies sounds cut off by cell phones might carry more information than previously thought: The human voice routinely produces sounds at frequencies above 5000 hertz, but it has long been assumed that this treble range, which includes high sounds such as cricket chirps, is superfluous to the understanding of human speech. Now researchers from the University of Arizona and the University of Utah are taking a second look this underappreciated range. Their research reveals that people can glean a large amount of information, including the identification of familiar songs or phrases, from just the higher frequencies. The work may prompt a re-evaluation of how much spectrum is in fact necessary to carry the full meaning of the spoken word. Although current cell phone technology only transmits frequencies between 300 and 3400 hertz, musicians have known for decades that an unbalanced or cut-off treble range can ruin the quality of vocals at concerts. The researchers recorded both male and female voices singing and speaking the words to the U.S. national anthem, and then removed all the frequencies below 5700 hertz. When volunteers listened to the high-frequency-only recordings, they were able to identify the sex of the voice, the familiar passages from the “Star-Spangled Banner,” and whether the voice was singing or speaking the words. The presentation 5aSCb3, “Perceptually relevant information in energy above 5 kilohertz for speech and singing,” will be presented in a morning session on Friday, Nov. 4.
Abstract: http://asa.aip.org/web2/asa/abstracts/search.oct11/asa999.html
MORE INFORMATION ABOUT THE 162nd ASA MEETING
Special “hands-on” Halloween education outreach session: Monday, Oct. 31:
Acoustics has a long and rich history of physical demonstrations of fundamental (and not so fundamental) acoustics principles and phenomena. In this session, the Acoustical Society will organize a set of “hands-on” demonstrations for a group of middle school students from the San Diego area. The goal is to foster curiosity and excitement in science and acoustics at this critical stage in the students' educational development and is part of the larger “Listen Up” education outreach effort by the ASA. Each station will be staffed by an experienced acoustician who will help the students understand the principle being illustrated in each demo. Demos will be run in parallel, so students can break into small groups to encourage questions and spend more time on demos that interest them. The session will have a Halloween theme with decorations and costumes!
The Town and Country Hotel is located at 500 Hotel Circle North, San Diego, California, 92108. Reservations: 1-800-772-8527; Main Number: 1-619-291-7131.
###
USEFUL LINKS:
Main meeting website:
http://acousticalsociety.org/
Searchable index:
http://asa.aip.org/asasearch.html
Hotel site:
http://www.towncountry.com/index.cfm
Webcast registration and viewing:
http://www.aipwebcasting.com
WORLD WIDE PRESS ROOM
In the week before the meeting, the ASA's World Wide Press Room (www.acoustics.org/press) will be updated with lay-language papers, which are 300-1200 word summaries of presentations written by scientists for a general audience and accompanied by photos, audio, and video.
PRESS REGISTRATION
The Acoustical Society will grant free registration to credentialed full-time journalists and professional freelance journalists working on assignment for major news outlets. If you are a reporter and would like to attend, contact Charles E. Blue (cblue@aip.org, 301-209-3091), who can also help with setting up interviews and obtaining images, sound clips, or background information.
ABOUT THE ACOUSTICAL SOCIETY OF AMERICA
The Acoustical Society of America (ASA) is the premier international scientific society in acoustics devoted to the science and technology of sound. Its 7,000 members worldwide represent a broad spectrum of the study of acoustics. ASA publications include The Journal of the Acoustical Society of America (the world's leading journal on acoustics), Acoustics Today magazine, books, and standards on acoustics. The society also holds two major scientific meetings each year. For more information about ASA, visit our website at http://www.acousticalsociety.or
Media Contact
More Information:
http://www.acousticalsociety.orAll latest news from the category: Event News



Newest articles

A universal framework for spatial biology
SpatialData is a freely accessible tool to unify and integrate data from different omics technologies accounting for spatial information, which can provide holistic insights into health and disease. Biological processes…

How complex biological processes arise
A $20 million grant from the U.S. National Science Foundation (NSF) will support the establishment and operation of the National Synthesis Center for Emergence in the Molecular and Cellular Sciences (NCEMS) at…
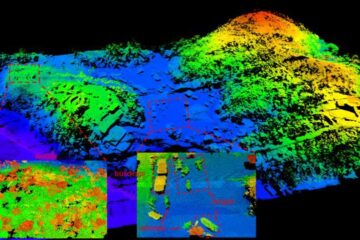
Airborne single-photon lidar system achieves high-resolution 3D imaging
Compact, low-power system opens doors for photon-efficient drone and satellite-based environmental monitoring and mapping. Researchers have developed a compact and lightweight single-photon airborne lidar system that can acquire high-resolution 3D…

